

TKE 2012 Tutorial: Friday 22nd June 2012
Corpus-based Terminology Processing
Speakers:
M. Teresa Cabré, M. Amor Montané and Rogelio Nazar
{teresa.cabre,amor.montane,rogelio.nazar}@upf.edu
Venue: Workshop session of the Terminology and Knowledge Engineering Conference (TKE 2012) to be held at Universidad Politécnica in Madrid.
Audience Profile: Terminologists, translators, linguists and other language and terminology related professionals.
Technical Requirements: In this tutorial we will embark on the creation of a glossary with the software Terminus. In order to take the most of the tutorial, you will need to carry a laptop in order to connect to this web application. We encourage participants to decide in advance what kind of glossary they would like to develop, at least the language, the domain and the intended users. To save time, the best is to begin compiling a corpus of the domain (it does not have to be very big) in simple text format. It would be a great advantage for the participant to bring a list of terms of the domain to use as examples to train our program in order to use it for automatic terminology extraction. This list of terms is simply a text file with one term per line. The larger the list, the better the results. At least two hundred terms are needed, one thousand is recommended. Please notice that at the moment we are only working in a limited number of languages (English, Spanish, French and German), but since our terminology extraction models are statistically based, it is relatively easy to start working in another language. If you are interested in a particular one, please let us now as soon as possible.
1. Introduction
In this tutorial we will offer an introduction to Corpus Based Terminology both in theory and practice. In the first part, we will present some basic notions about terminology work and in the second part we will concentrate on the practical aspects of Corpus Based Terminology based on a software especially designed for this purpose according to the general guidelines of the Communicative Theory of Terminology (Cabré, 1999), henceforth TCT. The TCT adopts a linguistic approach to terminology taking also cognitive and discursive aspects into account; therefore its object of study are terms conceived in the context of specialized discourse. For the TCT, a linguistic approach to terminology is a corpus-based approach, in the line of advocates of corpus linguistics (Sinclair, 1991; Sager, 1991; McEnery & Wilson, 1996; etc.). This means that the TCT is not only interested in prescriptive terminology, i.e. the terminology established by standards or found in official databases but also (and particularly) in those terms that are actually used in L.S.P. (Language for Special Purposes) corpora by field experts. In other words, the TCT not only adopts an in vitro approach but is also interested in terms in vivo.
In the second part of the tutorial, we will go from theory to practice, and we are going to explain the various processes of corpus-based terminology work. This practical module will be based on the Terminus software, which was developed through a collective effort of linguists and programmers of the University Institute for Applied Linguistics of Universitat Pompeu Fabra in Barcelona. Terminus is a web based platform where the user will find tools for the whole terminology work-flow, including the compilation and analysis of corpora, terminology extraction as well as the elaboration of a database to store and retrieve terminological records.
The motivation behind Terminus is linked to our experience
in teaching terminology, especially in the scenario of the elaboration of multilingual terminological
projects based on corpora. We noticed that there was a mismatch
between the ideas we were transmitting to our students
and what they really could do in practice with the tools currently available in the market.
By the same token, we also noticed that the execution of such projects involve notions that are too
technical or abstract to be explained just with words. Consequently,
we started to devise a computational tool that would help students better grasp complex notions by
conducting their own experimentation, i.e. learning by doing.
2. Foundations of Corpus-based Terminology
The goal of a theory of terminology is to produce formal, semantic and functional descriptions of the lexical units having terminological value as well as to explain their relation with the rest of the units of the linguistic system. The TCT, as already mentioned, is interested in the living terminology, that is, the units that are effectively used by experts in specialized communication. As a linguistic theory of terms, the TCT conceives its object (i.e., terms) as cognitive units instantiated as lexical units in natural language. This is a multidimensional and variationist theory that puts the emphasis upon the communicative aspect of the use of terms, to the extend that it proposes a depart from a terminological theory based on designations to a theory of communication. We conceive, therefore, the terminological unit as a three-fold polyhedron having a the cognitive component (the concept), a linguistic component (the term) and a communicative one (the situation). Terminology, thus, is no longer seen as an autonomous theory but as an interdisciplinar one, because terms can be the object of study of a theory of language, a theory of knowledge and a theory of communication.
By definition, a corpus-based approach to terminology is oriented towards the analysis units that occur naturally in specialized texts to communicate expert knowledge. As already said, as linguists we are interested in the living terminology, and by carrying out empirical analyses we discover that terminology is much more complex than it has been traditionally assumed. Much like it occurs in general language, in specialized texts we also find synonymy, ambiguity, vagueness, periphrases, redundancy and systems of term variation taking place at different levels. On the face of this evidence, the notion of univocity (according to which concepts are ahistorical and language independent entities with a one-to-one correspondence with particular terms in different languages) becomes untenable. As a consequence, a theory of terminology must assume that variation is an essential property of the communication between experts and both terms and concepts must be studied in their dynamic interplay.
A useful metaphor to express this idea could be the kind of research that biologists conduct: they take samples and analyze, describe and classify living creatures, and only then attempt to produce a systematic theory. They would not attempt to describe how creatures should be according to a general theory without considering empirical evidence. Similarly, in a linguistic analysis we assume that insights provided by informants (in this case, the experts) can be complemented with the analysis of L.S.P. corpora.
3. Empirical analysis
As already mentioned in the introduction, our empirical analysis of corpus will be based on the Terminus Suite, which is a web-based application for corpus analysis and term extraction and management (a snapshot of the system's home page is depicted in Figure 1). Using this program, we will proceed to undertake all the steps to be followed in a typical terminological project, of which the most important ones are explained in this section, resulting in a glossary as the final product.
The first step of the process is the definition of the terminological project, where a number of important decisions have to be made, such as the selection of the domain field of interest for the glossary as well as the main language of the entries and the language or languages of the equivalences and, most importantly, which will be audience targeted by our terminological product (the communicative situation). Once these decisions have been made, the following step is to compile an appropriate corpus to work with, that is, a sample of specialized documents of sufficient size and quality to be considered representative of the domain in question (Section 3.1.).
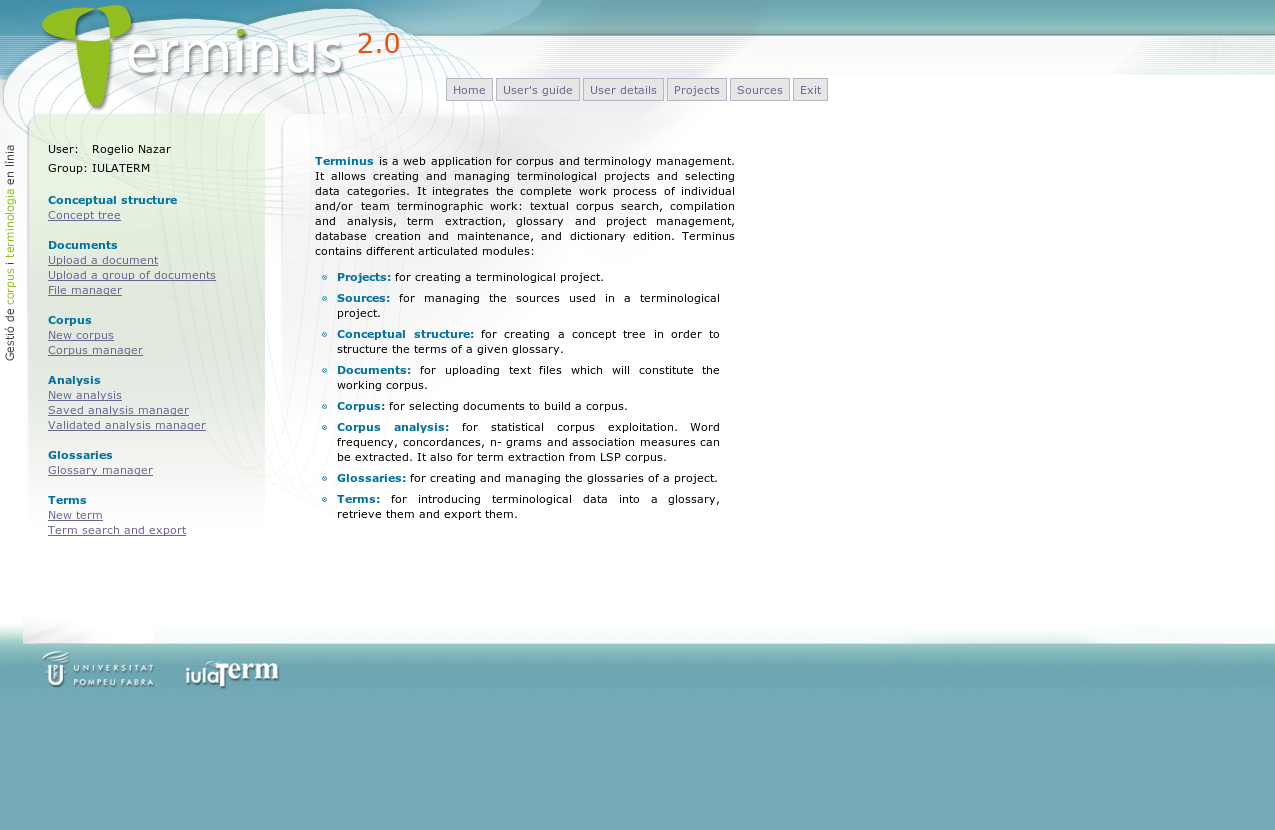
Figure 1: Terminus' home page
3.1. Corpus compilation
As mentioned in the previous section, the purpose of gathering a corpus of documents of the domain in question is threefold: firstly, as terminologists we need a first hand experience with the data to become familiar with the type of language of the domain, an indispensable experience that will complement the information obtained by interviewing experts. Secondly, this corpus is needed to conduct different statistical analyses of the vocabulary as well as terminology extraction. Finally, texts will also be used to obtain complementary information about the terms such as semantic, syntactic or collocational clues, among others.
Ideally, the corpus to be analyzed should be large enough to be considered representative of the domain. Unfortunately, there is no precise mathematical formula to determine what should be the size of a corpus to guarantee the sample's representativeness (though there are some approximations; see for instance Biber, 1993). As a general rule, corpus linguists say Big data is better data; thus, the corpus should contain as many documents as possible, because the bigger it is, the more terminological units it will contain and the more reliable our conclusions will be.
Leaving the dimensions of the corpus aside, perhaps the most important question regards the qualitative aspect. What should be an ideal corpus of the domain we are studying? The first step when we approach a new area of knowledge is to identify the publications of reference. Where do the experts publish their documents? This is probably the best way to compile an L.S.P. corpus, but probably not the most practical. Sometimes, for instance, the documents are not available on electronic format and thus the cost of the OCR scanning and subsequent manual correction becomes prohibitive. In such a case, one should consider using the web to search for documents using some terms as a query expression. Terminus will let the user decide for the best way to compile the corpus, either by uploading files previously compiled by the user, or selecting one of Terminus' options to download documents using web search engines. This latter option can be useful for downloading large amounts of data from the web, but it would be highly advisable to undertake a manual examination afterwards in order to eliminate irrelevant documents.
3.2. Concept structure design
During the first phases of the analysis, it might be useful to develop the concept structure of the particular domain under study. This can help the analyst, who is usually not an expert, to clarify the conceptual hierarchy of such domain. In other words, the conceptual structure represents the process by which the terminologist acquires knowledge on the domain s/he is going to study.
Among its first functions, Terminus contains a concept structure module for the design of the domain's concept tree (snapshot in Figure 2). Nodes will be labeled by the terms of the field and the connexions between them will reflect the relations between concepts. This information, entered by the user in a graphic form, will be later encoded in a logical form by the program (in XML syntax) in such a way that it could be, eventually, treated by other systems.
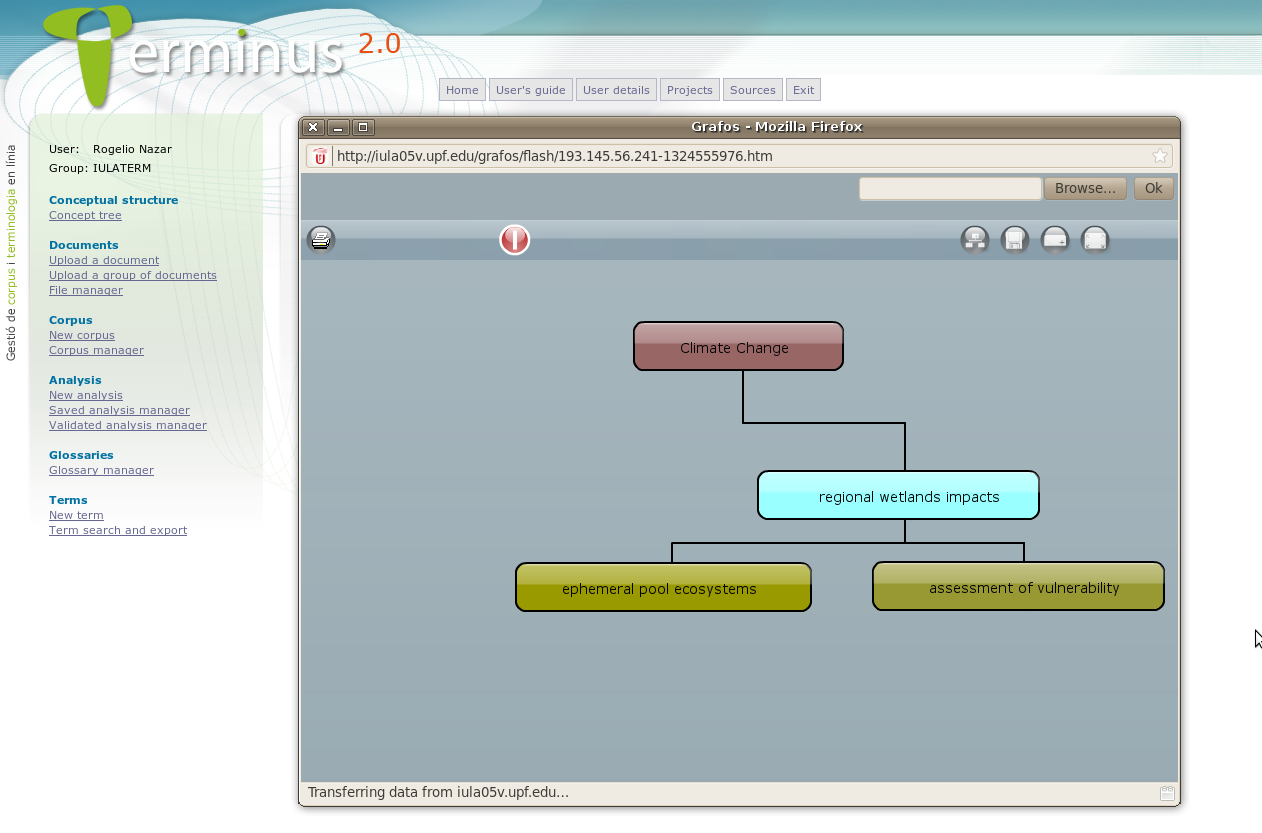
Figure 2: Terminus' concept structure module
3.3. Corpus exploration
Once the user has defined and compiled the corpus, Terminus offers different possibilities for the analysis of the vocabulary, each of them described in detail in the following subsections: the extraction of concordances (or Key Word in Context), explained in Section 3.3.1.; the sorting of the vocabulary of the corpus (words or n-grams) by frequency or by statistical measures of association, in Section 3.3.2. and, finally, the automatic extraction of terminology, in Section 3.3.3.
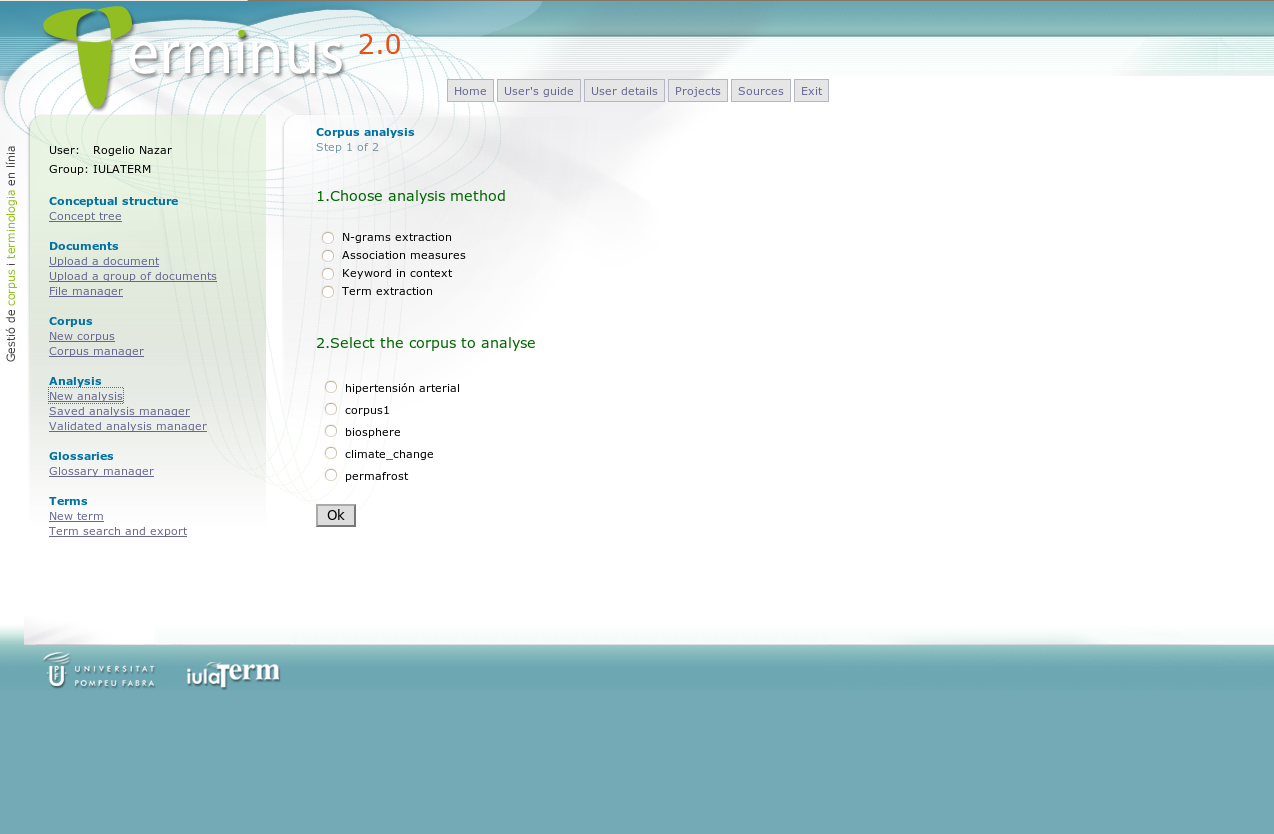
Figure 3: Different tools for corpus exploitation
3.3.1. Key Word in Context
The Key Word in Context search (KWIC), also called concordance extraction in the field of corpus linguists, is one of the simplest kinds of corpus analysis. It consists in the extraction of contexts of occurrence of a given query expression (i.e., the term), the context being a sentence or an arbitrary number of words on the left and right. Concordances can be extremely helpful to quickly grasp an idea of the meaning of a term by observing how the experts use such expression in real texts. They can also be used to analyze the collocations of the term or to see with which other terms it is conceptually associated.
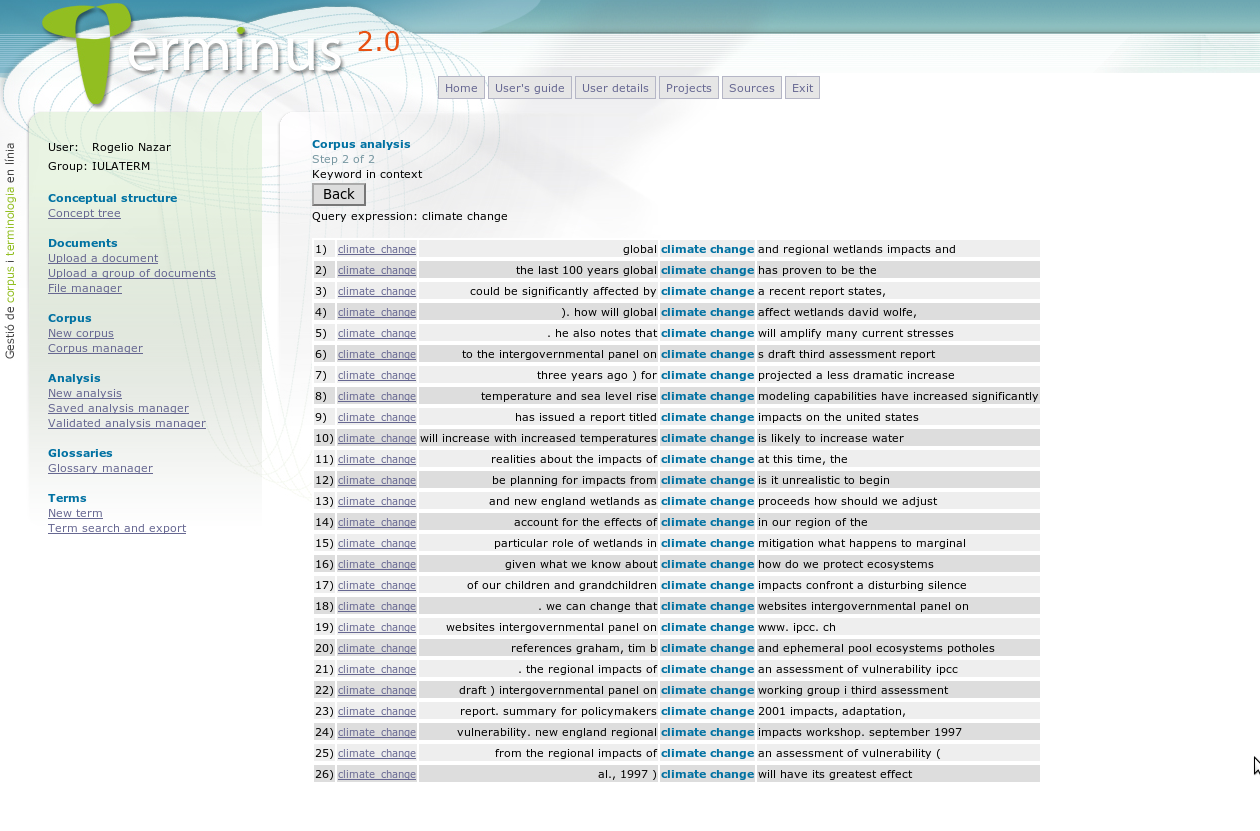
Figure 4: Key Word in Context
3.3.2. Sorting the Vocabulary of the Corpus
Sorting the vocabulary of the corpus is another strategy for the exploration of the corpus. In this stage, the program will offer the possibility of sorting words or sequences of words (n-grams) alphabetically, by decreasing frequency order or by using statistical measures of association which will highlight those sequences of words that have a significant tendency to appear together in the corpus.
Sorting the vocabulary in this way is a fairly simple procedure to discover multi-word terminology, collocations and phraseological units of various types. For the automatic extraction of terminology, however, Terminus has a specific function, which will be described in the next section.
3.3.3. Term Extraction
Automatic Terminology Extraction is one of the most active areas of research in terminology. It consists in the design of computational algorithms to extract terminological units from texts. This is a highly technical area of expertise on its own, and in spite of decades of efforts (see, for instance, Justeson & Katz, 1995; Kageura & Umino, 1998; Bourigault et al, 2001) to our knowledge there is still no consensus on which should be the best strategy for the extraction of terms, and the solution to this problem remains an open question.
Terminus incorporates its own original algorithm for terminology extraction (see a snapshot of the term extraction module in Figure 5). As it occurs with most term extractors, the results need human validation, because not all the yielded candidates will be real terms. However, there is no doubt that the quality of the results of the term extractor is superior than what could be obtained by extracting terminology with the functions described earlier in Section 3.3.2.
We will not delve into the details of how the program works because it would be out of the scope of this tutorial (for a description, see Cabré & Nazar, to appear). As a general view, however, we can say that it is a program that learns from examples provided by the users. In a phase prior to the analysis, the user is expected to train the program by uploading lists of terms of the domain of interest in a given language. With this list, the program will develop a mathematical model of the terms of the domain. Once the program is trained, it will be ready to extract any number of terms from that domain. The user may refine the program's learning process by progressively re-training it with new terms extracted from the corpus. The most interesting aspect of this procedure is that, as it is a web-based application, what Terminus learns from one user is shared and benefits of all its users. In this way, the program is constantly learning with the help of the community of terminologists and can adapt to new languages and domains without the need of of changing the program itself.
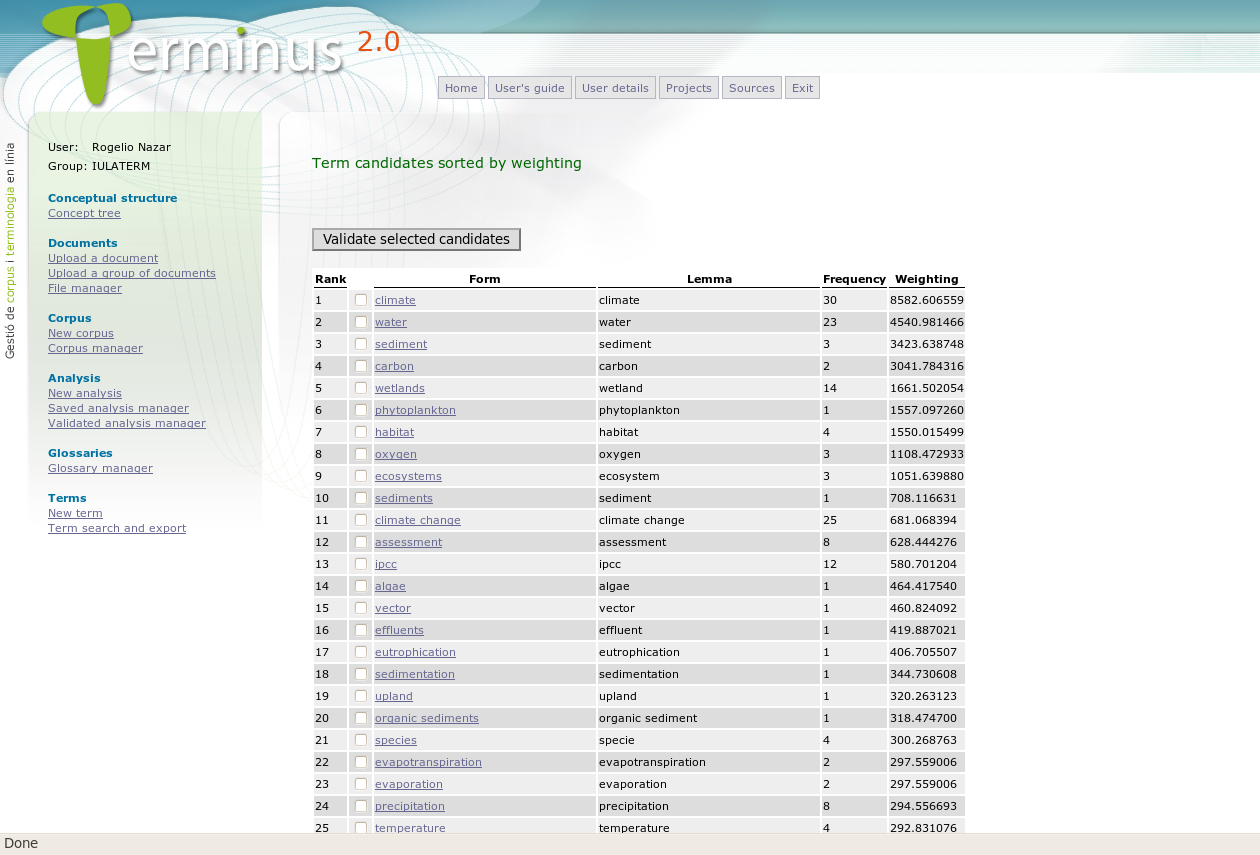
Figure 5: Term extraction
3.4. Glossary Creation
The creation of a glossary entails a series of important decisions. Terminus has a built-in glossary model, including the most typical fields of a glossary, such as the grammatical category of the term, its source, contexts of occurrence, equivalences, collocations, among many others. In addition, the user can configure his or her own glossary, customizing, eliminating, or creating new fields. This design aims at offering some minimum guidelines for the creation of glossaries to novice users, and at the same time maximum adaptability to the requirements of expert users in order that their glossary meets their specific needs or those of the intended end-users.
3.5. Term management
Once the fields of the glossary have been defined and the program configured accordingly, the term management phase consists in the creation of the terminological records and the completion of the records with term-related information. Once the compilation of the glossary has finished, the final step is to export the glossary in one of the different file formats available. For human readers, PDF as well as HTML formats are the most convenient (see an example of a terminological record in HTML shown in Figure 6). By contrast, users interested in exporting the data with the goal of importing it later in another database software may prefer other formats such as XML or CSV.
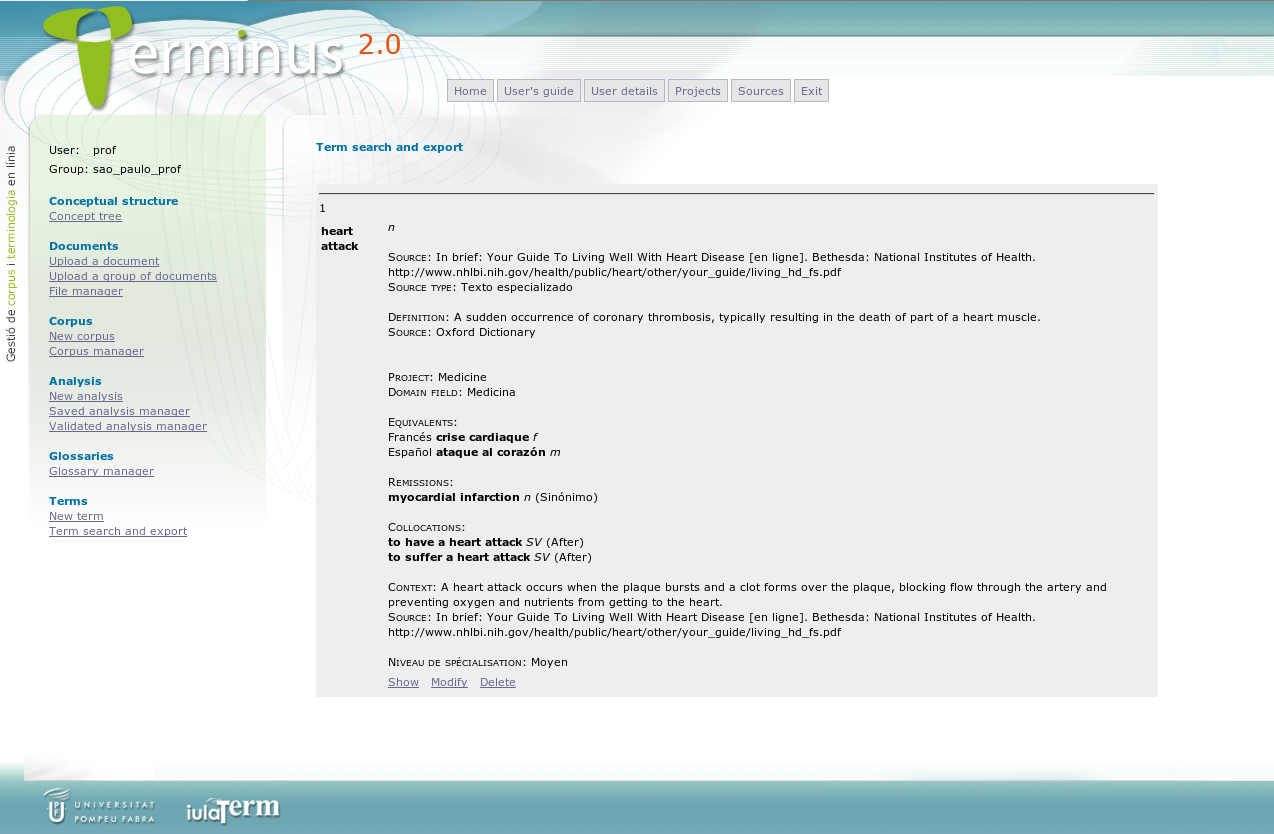
Figure 6: Retrieving database records
4. Conclusions
This Tutorial was intended to present
to the community of terminology related professionals
a newly developed tool for corpus based
terminology work. Terminus is an integral system used for the whole work-flow,
from the compilation of a corpus to the edition of
a glossary, including the analysis and exploitation of textual and terminological data
as well as the elaboration of the conceptual structure that
helps to select and organize the terms included in the glossary.
All of these stages have been briefly described in this tutorial.
As final remark, we would like to mention the fact that Terminus is
conceived as a modular system. It is constituted by independent modules
that can be used separately; thus, it is an adequate tool for users
with different profiles and needs. Terminus' adaptability is reinforced
by the fact fields of the terminological records can be customized to
meet a wide range of terminological needs.
References
Biber, D. (1993). Representativeness in Corpus Design.Literary and Linguistic Computing, 8 (4): 243-257.
Bourigault, D.; Jacquemin, C.; L'Homme, M-C. (eds.) (2001). Recent Advances in Computational Terminology. Amsterdam: John Benjamins.
Cabré M.T. (1999). La terminología: representación y comunicación. Elementos para una teoría de base comunicativa y otros artículos. Barcelona, Universitat Pompeu Fabra, Institut Universitari de Lingüística Aplicada.
Cabré, M. T. (2003). Theories of terminology. Their description, prescription and explanation. In: Terminology, 9(2): 163-200.
Cabré. M.T.; Nazar, R. (to appear) Supervised Learning Algorithms Applied to Terminology Extraction. In Proceedings of TKE 2012, Madrid, 20-21 June.
Justeson J.; Katz, S. (1995). Technical terminology: some linguistic properties and an algorithm for
identification in text. Natural Language Engineering, 1(1): 927.
Kageura, K.; Umino, B. (1998). Methods of Automatic Term Recognition.Terminology, 3(2): 259-289.
McEnery, T.; Wilson, A. (1996). Corpus Linguistics: An Introduction. Edinburgh University Press.
Sinclair, J. (1991). Corpus, concordance, collocation. Oxford University Press.
© INSTITUT UNIVERSITARI DE LINGÜÍSTICA APLICADA - UNIVERSITAT POMPEU FABRA, Roc Boronat 138, 08018 Barcelona